一、数据集和模型下载地址
全部模型和数据集可在我的NAS 中自行索取,地址: 唇语模型
二、文献翻译
介绍
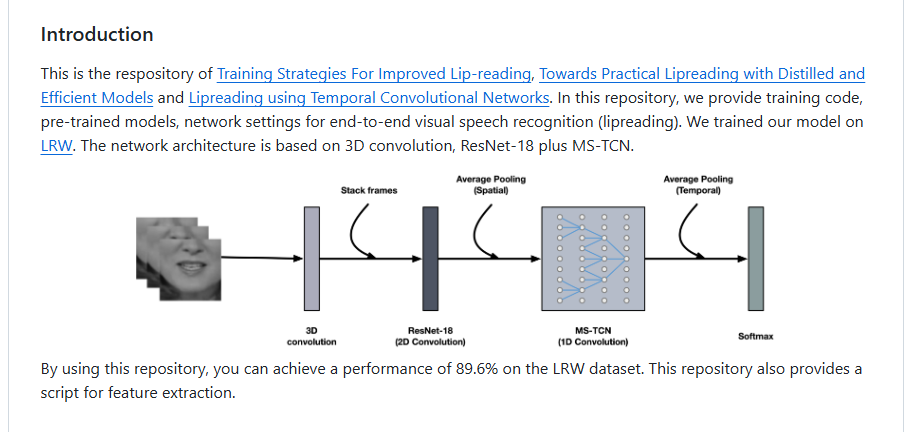
本项目的内容为改进的唇读训练策略,实现唇读的高精度高效模型,使用时间卷积网络实现唇读。在这个项目中,我们提供了 实现端到端的视觉语音识别(唇读)的代码,预训练的模型,网络配置。我们基于LRW 数据集训练了我们的模型。这个卷积网络是基于3D 卷积,ResNet-18 plus MS-TCN 实现的
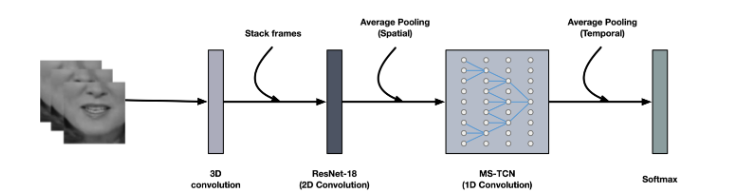
通过使用本项目,你可以在LRW 数据集上达到 89.6 的准确率,同时本项目还提供了一个用于提取特征的脚本

预处理
如我们论文所叙述的,LRW 数据集中每个视频都是按照下面的步骤进行处理的
(1) 进行面部检测,识别人脸的位置
(2)从每一帧中抠出人脸,并且旋转使得人脸的方向正常
(3)从每帧中的人脸图像中裁剪出 96 X 96 像素的 嘴部ROIS , 使得嘴部区域始终大致位于裁剪的图像的中心
(4)把裁剪后的图像转换成灰度图片
你可以运行 preprocessing 文件夹中的提供的 预处理脚本来提取嘴部的ROIS
如何准备环境
1.把当前项目复制到一个文件夹下面,我们推荐您把这个文件夹的位置设置成环境变量 TCN_LIPREADING_ROOT
git clone --recursive https://github.com/mpc001/Lipreading_using_Temporal_Convolutional_Networks.git2.安装需要的依赖
pip install -r requirements.txt
如何准备数据集
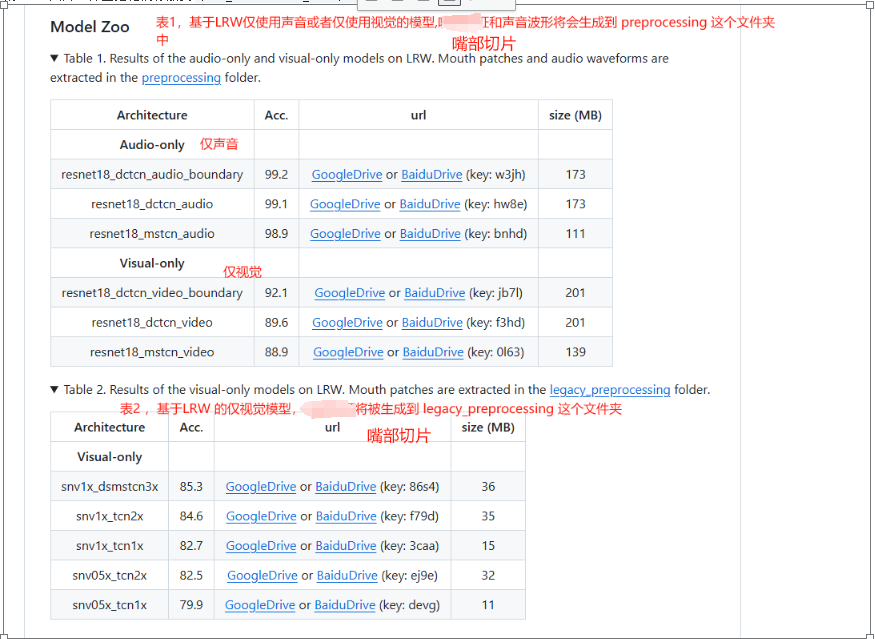
1.首先你需要从Model Zoo 这个网站下载预训练的模型,并且把模型放到$TCN_LIPREADING_ROOT/models/ 这个文件夹下面
2.对于只需要使用声音的实验,请通过使用 preprocessing 文件夹下的 extract_audio_from_video.py 这个脚本预先处理好声音波形,并且把他们保存到 $TCN_LIPREADING_ROOT/datasets/audio_data/.
3.对于表1 中提到的VSR 基准, 请从Google 网盘或者百度云盘下载我们预先计算的标注数据,并且把他们解压到 $TCN_LIPREADING_ROOT/landmarks/ 这个文件夹,请使用 preprocessing 文件夹下的 crop_mouth_from_video.py 这个脚本来预处理嘴部的ROIs 图片,并且把他们存放到 $TCN_LIPREADING_ROOT/datasets/visual_data/.
4.对于表2 中提到的VSR 基准,请从Google 网盘或者百度云盘下载我们预先计算的标注数据,并且把他们解压到 $TCN_LIPREADING_ROOT/landmarks/ 这个文件夹,请使用 legacy_preprocessing 文件夹下的 crop_mouth_from_video.py 这个脚本来预处理嘴部的ROIs 图片,并且把他们存放到 $TCN_LIPREADING_ROOT/datasets/visual_data/.

如何训练模型
1.训练仅基于视觉的模型
CUDA_VISIBLE_DEVICES=0 python main.py --modality video \
--config-path {MODEL-JSON-PATH}\
--annonation-direc {ANNONATION-DIRECTORY} \
--data-dir {MOUTH-ROIS-DIRECTO}
2.训练仅基于声音的模型
CUDA_VISIBLE_DEVICES=0 python main.py --modality video \
--config-path {MODEL-JSON-PATH}\
--annonation-direc {ANNONATION-DIRECTORY} \
--data-dir {AUDIO-WAVEFORMS-DIRECTORY}
我们把初始的包含时间戳(.txt)的LRW数据集的文件夹叫做 .
3.从上一个检查点恢复
你可以将检查点的路径(.pth 或 .pth.tar) 通过参数 -- model-path 传入,并且将 --init-epoch 的值置为1 来继续训练
如何测试模型
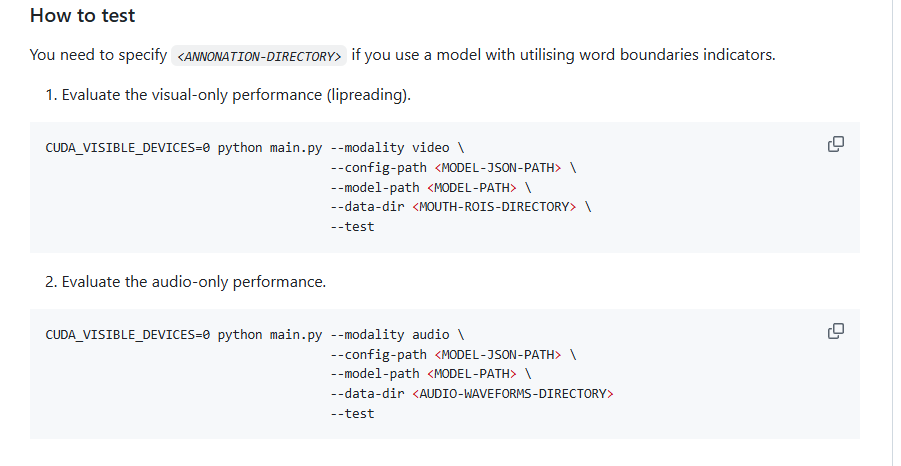
如果你需要使用具有单词边界指示符的模型,你必须指定
1.评估仅视觉模型(唇读)
CUDA_VISIBLE_DEVICES=0 python main.py --modality video \
--config-path {MODEL-JSON-PATH}\
--model-path {MODEL-PATH}\
--data-dir {MOUTH-ROIS-DIRECTORY} \
--test
2.评估仅声音模型
CUDA_VISIBLE_DEVICES=0 python main.py --modality audio \
--config-path {MODEL-JSON-PATH}\
--model-path {MODEL-PATH}\
--data-dir {AUDIO-WAVEFORMS-DIRECTORY} \
--test

如何提取特征值
我们假设你已经正确裁剪了嘴部的切片,并且把他们存到了.嘴部特征将被保存为.npz 的格式
从 ResNet-18 网络中提取嘴部特征:
CUDA_VISIBLE_DEVICES=0 python main.py --modality video \
--extract-feats \
--config-path {MODEL-JSON-PAT} \
--model-path {MODEL-PATH} \
--mouth-patch-path {MOUTH-PATCH-PATH} \
--mouth-embedding-out-path {OUTPUT-PATH}
三、项目复现
1. 下载模型,标注的数据,数据集
这里我们需要复现的是通过视觉模型进行识别的特征提取。我们选用精度最高的模型 lrw_resnet18_dctcn_video_boundary.pth
首先需要下载的是 lrw_resnet18_dctcn_video_boundary.pth,将它下载到 项目的 models 文件夹下
根据项目说明,该模型使用的是LRW-1标注的数据,因此把 LRW_landmarks.zip 下载解压到 landmarks 文件夹下面
将 LRW-1000 数据集下载,存到 datasets 文件夹下(新建文件夹 LRW_1000),注意一共5个压缩文件包,需要分别解压
2.准备数据集
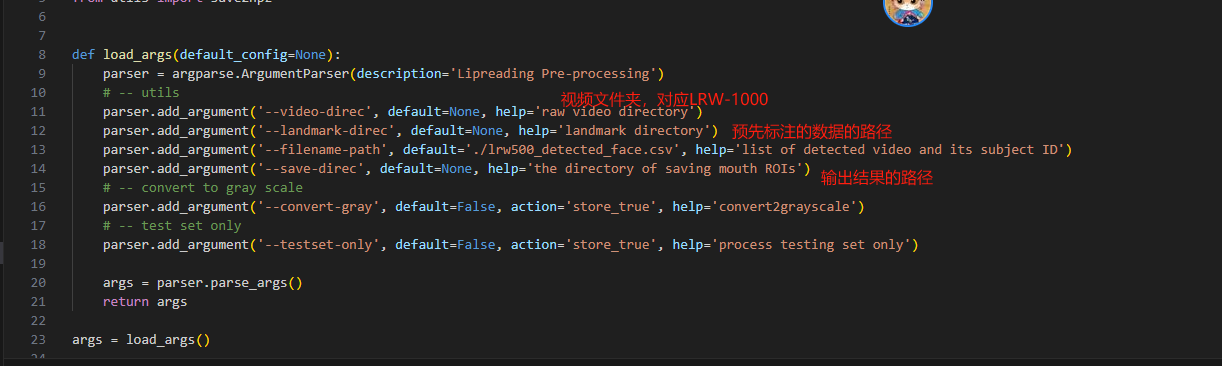
按照项目说明,我们打开 preprocesing 文件夹下 crop_mouth_from_video.py , 查看这个文件的内容
执行下面的代码,开始对数据集进行预处理(注意更改参数路径)
CUDA_VISIBLE_DEVICES=0 python3 crop_mouth_from_video.py --video-direc=/data/Lipreading/datasets/LRW_1000/ --landmark-direc=/data/Lipreading/landmarks/LRW_landmarks/ --save-direc=/data/Lipreading/datasets/visual_data/ --convert-gray
如下图所示,正在对数据集进行预处理
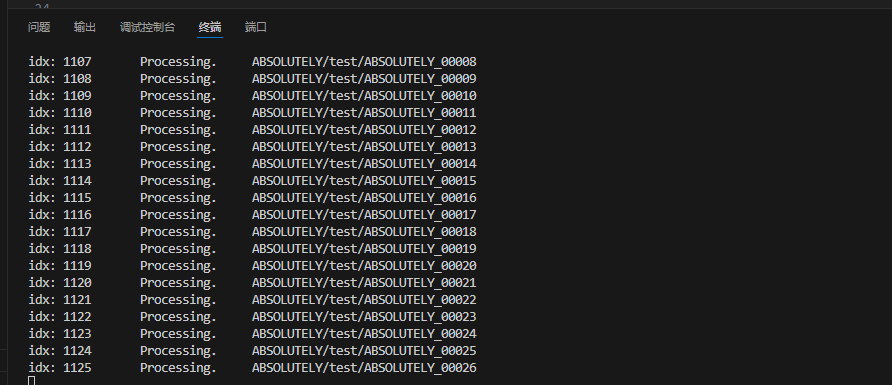
数据集预处理期间,将占用约2G 左右的显存
1.注意开启 CUDA_VISIBLE_DEVICES=0, 否则服务器会只使用 CPU, 速度非常的慢
2.注意请记得加上 --convert-gray 这个参数,否则训练模型时会出错 详见 issues39
3.开始训练模型
参考项目的说明文件,训练代码如下(使用 resnet18_dctcn_video_boundary 这个预训练的模型)
CUDA_VISIBLE_DEVICES=0 python3 main.py --modality video --config-path=/data/Lipreading/configs/lrw_resnet18_dctcn_boundary.json --annonation-direc=/data/Lipreading/datasets/LRW_1000 --data-dir=/data/Lipreading/datasets/visual_data